以前看到的類似控制用的框架,可用在PC based控制系統中,原文連結:Tiny Framework for Parallel Computing。
本文中提到的範例有點複雜,測試時可先用較少的命令來看它實際上的執行程序。另外還有一個可供參考的框架是曹永誠先生提出的共通控制程式架構,這裡有另外的相關文章可參考。
曹先生的控制架構相對起來較完整,或許也可以基於此框架來擴充之。
- 辭不達義的地方所在多有,無法理解時請參考原文…
On Article’s Update
原先我寫這篇文章是為了展示一個小型的可用在機器及行程控制的框架,不過有個聰明的讀者建議,我決定從善如流來擴展定義,是的,這框架提供的是一個簡單的平行計算架構平台。
Introduction
在我的軟體開發生涯中,有好幾次我需要處理有關行程/機器控制的專案。每次我都會觀察到神奇的相似現象。小型公司設計及製造自動化機器,這些公司有各自領域的專家,電子或軟體工程師,機構動作控制的很好。但是到了PC-based的流程控制軟體時,專案可能會出現問題。這些軟體很難理解及維護,更不用說更新機器的版本/世代時。所以,在流程控制軟體上出了什麼問題?
我老實的說,這個問題是基於一般化的軟體開發及設計。至今我所見的每個公司都重零開發自己的流程控制軟體,是的,一開始時它看起來非常簡單:將幾個定義良好的操作連結起來!PC端的軟體工程師主要努力集中在動作本身的開發,實作與控制器,部份軸控,視覺控制和隨後的影像分析等相關的協定。當所有這些開發階段完成時,突然間它們的相互作動不如預期,當嘗試實作正確的機構作動時,開發者面對的是缺乏彈性、臨時編寫的程式,這導致很難除錯及修正的結果。更糟的是,要對軟體除錯時,所有的開發者需要共用此昂貴的硬體。在某些狀況下,在硬體上除錯是不可能的。例如,考慮一個動作n秒的伺服馬達,需停止m秒後再作動,增加它的連續作動時間會導致過熱和隨後的損壞,所以開發者不能在馬達作動時因設置中斷而導致馬達作動過久。
無法開發合適的操作流程控制軟件會給公司造成巨大損失(相對於他們的預算)。 那麼應該如何防止這些損失並提高流程控制軟件的質量?
Background
為了達成這個目標,在開發流程控制軟體時我有以下幾點建議。
- 將整個程序分成不同的操作(如下所說的commands)
- 使用一般化的流程控制引擎,這個引擎處理commands並分析結果,這個引擎要基於一般化的框架,這個框架要提供統一的機制以執行順序式或平行式的commands、機器狀態分析及基於此分析所產生的新commands。除此之外,框架應支持command優先權、暫停/繼續command的執行、錯誤處理和日誌記錄等功能。
- 清楚的將命令和其處理器分離。除了更簡潔的邏輯和易於理解,這個規則提供了一個很好的架構優勢,通過分離開發者的任務以適當地做平行處理和執行緒同步,以及讓工程師理解command的性質,並能夠編寫command的執行方法。
- 每個command為它的執行及錯誤處理提供虛擬函式,這些函式會在特定繼承類別的command實作且被命令處理器執行。
- 每個command可能執行在實際或模擬模式,命令的模擬允許開發者以模擬的方式執行一些或所有命令來測試軟體。模擬方法可能針對機台模擬器或是模擬機器本身。
- 控制引擎被一個Singleton的ProcessorManager所管理。它主要負責Processor的建立和維護,及處理因執行命令所造成的狀態改變。
- 對引擎來說,內建的錯誤處理和日誌記錄是非常重要的。
我相信若是依照上述規則,一個小型的機器製造商能夠開發出很好的機台控制軟體。本篇文章中,我展示了一個依照上述規則的簡單且一般化的框架,並提供了兩個使用範例。
當設計一個框架時,開發者常會面對一個兩難的問題:為使用者提供最多的工具和方法,或者為他們提供最關鍵和複雜的開發手段,並允許使用者有最大的靈活性。在現實中,這總是需要折衷。對這個小型的流程控制框架,我選擇和第二種相似的架構。決定的設計“簡約”的框架。它表示這個框架應只具有對操作流程管理至關重要的特性。我認為在大多狀況下程式碼的簡潔性和可維護性是比效能更重要的。作為範例,可以考慮下Microsoft robotics Developer Studio[1],儘管它很有用,提供很多進階功能(例如,分佈式輕量級服務,可視化編程語言,神奇的視覺模擬環境等),這個龐大的框架因其安裝、使用和學習的複雜度,在工業上卻很少被使用。
Design
下面的區塊圖說明了此設計。
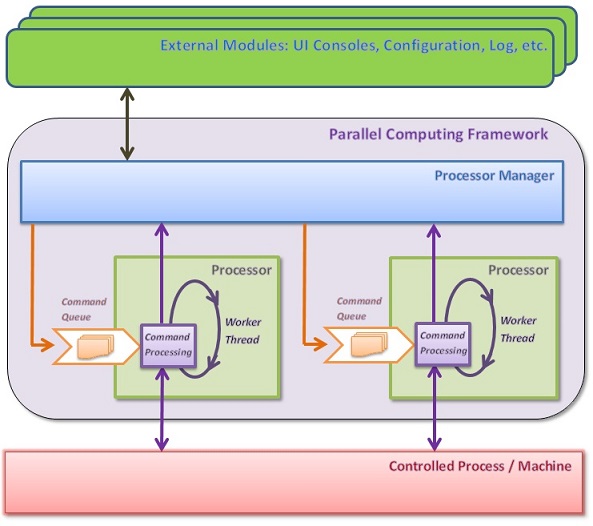
此框架主要由五種類型組成,命名如下:
- ProcessorManager
- Processor
- Command
- ParallelCommand
- Log
ProcessorManager 是一個singleton類別,負責建立和管理Processor, 它有一個內部類別ProcessorManager.PriorityQueue,負責依權限處理processors。對每個權限來說,ProcessManager會有一個相對應的PriorityQueue型別的實體,提供一個processors的佇列,及當前正在執行的processors的字典對應。PriorityQueue型別也支援暫停/繼續執行所有低於當前實體優先權的processors的能力。這個功能是預設的,但可以透過在建立ProcessorManager時將false代入Initialize()函式來關閉。實際對低於優先權的processor暫停/繼續執行的動作是由ProcessorManager來處理的。另一個processorManager型別的關鍵函式是基於當前受控process的狀態來決定命令執行流程,函式OnStateChanged()就是這個目的,它實作使用者提供的決策代理的同步函式呼叫。這個委託是由ProcessorManager型別的indexer提供的。
使用者也許會決定一次建立同一個優先權的數個Processor實體(通常在程式開始時)。這可能是有用的,因為建立新的processor意謂著建立它的執行緒,這是相對昂貴的操作。ProcessorManager型別的函式IncreaseProcessorPool()會建立新的processors,PriorityQueue型別支援processors池,從池中取得的processor可歸還回去,這是為了避免在建立新processor時建立的新執行緒。
Processor型別的主要工作是處理它自己的命令佇列及執行從佇列取出的命令,每個Processor型別的實體會在自己的執行緒中執行命令,此實體的特徵在於其唯一的Id和優先權,此Id是整數值(but for convenience appropriate enumerator may be used for some well-known values)。Processor實體將命令執行的整個機制封裝在其執行緒中,包括佇列管理、同步、錯誤處理、日誌記錄和適當的callback呼叫。執行完每個命令後,Processor呼叫如上所述的其執行緒中的context的同步函式ProcessorManager.OnStateChanged()。由於這個函式被所有processor同步呼叫,所以它要執行的委託函式應該要很快速(譯者:裡面不應有block命令或耗時的動作),以確保良好的性能。在ProcessorManager.OnStateChanged()呼叫之後,如果使用者提供了post-command-execution OnStateChangedEvent委託,此委託會被呼叫。因此,ProcessorManager和Processor的合作為使用者的callback提供了命令執行流程,有效地隱藏了對使用者來說很棘手的佇列和執行緒同步的細節。在準備執行命令前,委託應已被指定給processor,也就是說在呼叫函式StartProcessing()之前要完成指定。這通過取得Processor型別實體時帶給其第二個參數值false來完成,然後再指定OnStateChangedEvent委託,接著再呼叫StartProcessing()函式,範例程式中會展示此步驟。進入Processor佇列中的命令意味它們的非同步執行意涵,即它們會馬上被回傳,而實際的動作處理會稍後在processor的執行緒中作動。
上面描述的ProcessorManager和Processor型別,不受使用者變更的限制,應只提供做決定的callbacks。繼承自Command型別的子型別僅提供給行程/機器特定的功能,不像ProcessorManager和Processor,Command的子類別可以避免同步和其它棘手的事情,它們很簡單,Command僅涉及受控物件,因此甚至可由僅有有限的軟體能力的領域專家實作。另一Command的重要特性是它們提供實際或模擬執行的能力,子類別應覆寫ProcessReal()及ProcessMock()虛擬函式來提供實作。
控制框架的另一個重要特性是它支援Parallel地執行命令。這是使用特殊命令型別ParallelCommand:Command來實作的。在ProcessReal()及ProcessMock()中呼叫的ProcessParallel()函式中ParallelCommand將每個並行執行的命令推入新取得的processor佇列中,一旦命令完成,processor會自動回到process pool中。
日誌記錄使用相同的processor-command來實作。一般化類別Log實作ILog介面,並以使用者提供的繼承自抽像類別CommandLogBase:Command的資料做為參數。在Log類別的建構式中,它建立了一個自己的log processor,而每一個ILog.Write()覆載函式會推入繼承自CommandLogBase的命令至佇列中。Log processor的優先權是固定的,而使用者建立的processor的優先權應被指定,以確保命令執行和日誌記錄能均衡動作。在使用這個框架一段時間後,我建立要另建一個額外的特定格式的記錄檔。每個命令在它的開始跟結束時輸出記錄至此記錄檔,而每個processor的記錄放在不同的欄位,因此,這個記錄檔可以描述在processor中每個命令的執行順序。雖然目前框架中不包含日誌記錄,它對瞭解命令流程和除錯仍會有很大的幫助。SampleA的程式碼產生了這樣的檔案。
Code Samples
上述的框架位在ParallelCompLib 專案中,而目錄Samples下有兩個範例。兩個範例都實作了從具有不同優先權的processor所執行的繼承自Command的子類別的動作和日誌相關命令類別。SampleA展示了幾個順序和平行命令的執行,命令具有不同的處理時間(使用Thread.Sleep()函式定義),也展示了processor被歸還回processor pool中。SampleA的日誌記錄產生包含例程日誌和顯示每個processor的命令執行順序的輸出文件–_test.log,並展示了將processors歸還給pool及其隨後被重覆使用的記錄。而檔案_flow.log記錄了每個命令的開始及結束,Processor的ID顯示在括號中的最前面,隨後是命令的資訊。檔案中的每一筆記錄都有時間先後的關係,所以如果一開始只有一個processor在pool中,就可以很清楚的瞭解它被重覆使用的過程。觀察在檔案Program.cs開頭的define打開或注釋掉時的命令執行過程的差異是很有趣的,要從Visual studio中執行SampleA,請build後再執行。
讓我們來看一下SampleA程式,如下所示:
//#define _NO_LOWER_PRIORITY_SUSPEND
//#define _BIG_PROCESSOR_POOL
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Drawing;
using System.Threading;
using System.Threading.Tasks;
using IL.ParallelCompLib;
namespace SampleA
{
class Program
{
static void Main(string[] args)
{
#if _NO_LOWER_PRIORITY_SUSPEND
ProcessorManager.Initialize(false);
#endif
ProcessorManager.Instance.Logger = new Log<CommandLog>(LogLevel.Debug);
var priority = PriorityLevel.Low;
#if _BIG_PROCESSOR_POOL
ProcessorManager.Instance.IncreaseProcessorPool(priority, 15);
#endif
var evSynch = new AutoResetEvent(false);
CommandLog.dlgtEndLogging = (s) =>
{
if (!string.IsNullOrEmpty(s) && s.Contains("Z") && s.Contains("End"))
evSynch.Set();
};
var processor1 = ProcessorManager.Instance[priority];
ProcessorManager.Instance[ProcessorState.CommandProcessed] = (pr, e) =>
{
if (e.Cmd != null && e.Cmd.ProcessState != Command.State.NotYetProcessed &&
!string.IsNullOrEmpty(e.Cmd.Name))
{
// This event handler is always called after command has been processed.
// The call is performed in context of thread of the processor
// caused the event.
if (e.Cmd.Name == "M")
{
processor1.EnqueueCommand(new CommandS("Z"));
return;
}
if (e.Cmd.Name.Contains("->1"))
// After end of appropriate command processing processor is
// returned to pool.
// This has to be done as parallel task, outside of the processor's
// thread context.
ProcessorManager.Instance.ReturnToPoolAsync(e.Cmd.Priority,
e.Cmd.ProcessorId);
}
};
// After being taken from pool, processor2 constitutes different
// instance of Processor type.
var processor2 = ProcessorManager.Instance[priority, false];
processor2.OnStateChangedEvent += (pr, e) =>
{
if (e.Cmd != null && e.Cmd.ProcessState != Command.State.NotYetProcessed &&
!string.IsNullOrEmpty(e.Cmd.Name))
{
// This event handler is called only before return of this processor
// to the processor pool.
if (e.Cmd.Name == "_ParallelCommand" &&
e.Cmd.ProcessState == Command.State.ProcessedOK)
processor1.EnqueueCommand(new CommandS("H"));
// Usage of evSynch makes command "K" synchronous
if (e.Cmd.Name == "K")
evSynch.Set();
}
};
processor2.StartProcessing();
int si = 0;
int pi = 0;
processor2.EnqueueCommand(new CommandS(GetName("S", si++)));
processor2.EnqueueCommands(new Command[]
{ new CommandS(GetName("S", si++)), new CommandS(GetName("S", si++)) });
processor2.EnqueueCommandsForParallelExecution(new CommandP[]
{ new CommandP(GetName("P", pi++)), new CommandP(GetName("P", pi++)) });
processor2.EnqueueCommands(new CommandS[2]
{ new CommandS(GetName("S", si++)), new CommandS(GetName("S", si++)) });
processor2.EnqueueCommand(new CommandS("K"));
evSynch.WaitOne();
ProcessorManager.Instance.ReturnToPool(ref processor2);
// After processor returned to the pool it is stripped from its
// previous OnStateChangedEvent handler.
int processorsInPool = ProcessorManager.Instance.ProcessorsCount(priority);
processor2 = ProcessorManager.Instance[priority]; // command processor
processor2.EnqueueCommands(new CommandS[2]
{ new CommandS(GetName("S", si++)), new CommandS(GetName("S", si++)) });
processor2.EnqueueCommandsForParallelExecution(new CommandP[]
{ new CommandP(GetName("P", pi++)), new CommandP(GetName("P", pi++)) });
processor2.EnqueueCommand(new CommandS("M"));
evSynch.WaitOne();
ProcessorManager.Instance.Dispose();
}
static string GetName(string name, int n)
{
return string.Format("{0}{1}", name, n);
}
}
}現在讓我們來看一下SampleA的_flow.log日誌檔,檔案中最主要部份的格式很簡單。每個列表示一具有執行緒的的Processor,Processor的ID在括號中的第一區段,然後,以名詞表示命令的開始和結束,底線後面是命令的ID和名稱。為了簡單起見,Log processor(在我們的範例中其ID為0)中省略了log命令和ParallelCommand。每個Processor和Command通過遞增前一個ID來取得它們自己的ID,檔案中的Command的ID不是連續的,”缺少”的ID是屬於日誌Command。
註釋掉_BIG_PROCESSOR_POOL時SampleA的_flow.log日誌檔案的區段如下所示。在這種情況下,沒有預先建立指定優先權的processor pool。

在這種情況下,我們可以看到歸還到Processor pool的processor被重用。processor1是第一個建立的Processor,但在change event handler中,命令(即H和Z)在一段時間後分配給它。因此,該Processor具有ID(1),但僅出現在最後一欄中。具有ID(2)的processor2以順序處理CommandS型別的三個命令(即S0,S1和S2)開始。然後,同一個Processor分配有兩個CommandP命令(P0和P1)用於平行執行。ParallelCommand實體分別在新建立的processor(3)和(4)中執行命令。每個CommandP命令建立另一個processor - (5)和(6) - 以執行型別為CommandS的兩個連續命令。有趣的是,processor(2)僅在所有並行命令結束之後繼續其下一個連續命令S3,S4和K,這是由ParallelCommand設計引起的期望行為。然而,即使在平行命令結束之後,由processor(5)和(6)中的平行命令發起的順序命令也被執行。ParallelCommand命令的結束導致enqueue命令H到processor(1)。Enqueue操作在processor(2)命令S3開始之前發生,但是稍後由processor(1)實際執行命令H。因此S3的開始在H的開始之前。所有processor(3) - (6)被歸還到Processor pool。ParallelCommand歸還processor(3)和(4),而ProcessorManager change event handler呼叫函式ReturnToPoolAsync()將processor(5)和(6)返回到pool中。因為上面的四個processor被非同步歸還至Processor pool,它們在pool中的新順序是不可預測的。在範例AutoResetEvent evSynch.WaitOne()中,執行等待直到命令K結束。然後通過呼叫ProcessorManager的方法ReturnToPool()將processor(2)歸還給Processor pool。接續的命令由從我們已知的Pool中重新取得的processor執行。
當_BIG_PROCESSOR_POOL被取消註解時,預先建立了包含15個Processor的給定優先權的Processor pool。現在已經使用的處理器也被歸還至pool中。但是預先建立的process數量足夠多,無法觀察到這一點。有趣的是,在這種情況下,起始時所看到的命令的數量比前一個狀況多,這是因為處理器的建立導致許多的日誌命令,這些命令未顯示在_flow.log文件中。
SampleB程式控制Simulator WinForms應用程序。模擬器使用[2]中描述的DynamicHotSpotControl(with some modernizations)。模擬器充當WCF服務的主機,並從SampleB接收命令。為了觀察模擬器狀態的變化,使用[3]中描述的“智慧輪詢”技術。選擇這種方法來說明處理器的OnStateChangedEvent的使用以及具有低(低於日誌)優先權的長時間命令。開始的命令讓模擬器以適當的狀態和動態建立視覺物件,然後模擬器在每個滑鼠點擊一個可視對象時通知SampleB程式。ProcessorManager在其相應的callback過程讓模擬器的狀態變更,並使用CommandChangeState和CommandChangeDynamics回應給Simulator。要從Visual Studio運行SampleB和Simulator,您應該build後再同時用多個啟動項目來執行它們。
Demo
解壓縮後的檔案包含範例程式,SampleA.exe會展示SampleA,而SampleB,要先啟動Simulator.exe(它是WCF的伺服器),再執行SampleB.exe。
Discussion
要謹慎使用此框架的靈活性。在軟體中的許多地方使用太多排入命令佇列的處理器可能導致性能惡化甚致非預期的操作流程。”Keep it simple”原則不應該被忽略,不要因為我們的工具而讓事情變得更複雜。
Conclusions
本文介紹了平行計算的簡易框架,適用於機械和流程控制、遊戲、模擬器等操作流程的管理。框架提供了順序和平行命令執行,可受控的過程狀態分析,錯誤處理和日誌記錄的機制。它的使用讓開發者清楚地將命令和執行流程分開,並可模擬一些命令,而實際執行其它命令。此框架易於使用,並且可做為各種領域的平行計算應用的基礎。
Written with StackEdit.